Lowering Latency by Moving From Kafka to Redpanda

TLDR; we shaved 43% of our 99th-percentile latency by moving from kafka to redpanda. For a crypto spot and derivatives exchange like us it’s the difference of billions of dollars of daily trading volume. Any other firms in the financial services industry might be better off to replace kafka with redpanda. Integration was as simple as replacing the host:port pointing to Kafka with a host:port pointing to Redpanda.
Why did we chose Kafka at the beginning as means for event streaming and event store?
Imagine you’re running a large coffee beans retailer, with a warehouse full of various grades of beans. One day, there is a spike for demand, where everyone buys every single variety of coffee. In a short time, chaos ensues in the warehouse team, not knowing what kind of beans are left. All of a sudden, hundreds of your clients ordered the grade A coffee at the nearly the same time, with your team not knowing who would have the right for the limited amount of those grade A beans. These kinds of problems are even more profound in large-scale, big-data style companies, where billions of data are generated every second from some source and need to be further processed downstream by another service, such as the order and warehouse in our previous example. The question is, how do companies track and deliver these data in time, without any attenuation along the way, and with precision?
Technically speaking, there are some methods to try and send data over, the simplest of which is using manual database, either through pen-and-paper, or some kind of spreadsheet applications then sending it through snail mail or email. This has worked since the beginning of society, however there are some glaring problems besides the obvious speed of the transfer of information; data loss, scalability.
Lost messages may well have been the cause of defeats in wars or dollars lost in business, and unless the sender makes sure to manually add redundancy such as sending two messages at the same time, it becomes a potent downside. Sending two, however, may be very expensive and impractical. In addition, trying to send a million spreadsheet files to dozens of recipients in a minute is also impractical, the manpower needed to analyze and send the files are monstrous indeed, and the system might also crash, and thus our first problem. Being able to handle huge amounts of information and scale accordingly is also something that most data-based companies strive for.
A more elegant solution would be using online database servers, SQL or NoSQL for example. It is way more easily scaled, since adding servers, in most cases, could solve the problem. Also, multiple users can promptly access any data they need without necessarily having to add infrastructure. Some databases also provide redundancy, in case of data loss. Databases are generally well rounded solutions for many practical use cases. However, it falls short on cases where we need lightning-fast, real time data transfer between a source and a receiver. The process itself requires the source to authenticate the connection to the database, then write data to disk, then the retriever needs to authenticate their connection too to access the data in disk thus adding the time required. This is where streaming services come in.
Streaming services such as Kafka or Redpanda revolve around the ability of programs to utilize parallel processing, in which processes are done simultaneously in parallel in a system. In other words, a source may open multiple pipelines of data streams to a receiver, or to multiple receivers or vice versa, where a single receiver receives multiple data pipelines from many sources. This feat allows for almost real-time data streams to be sent and received.
Kafka is the de-facto standard in streaming service, used by big companies, such as Uber, LinkedIn, and Spotify to name a few. It allows multiple senders (called producers) to send data through dedicated pipeline streams (topics). Then receivers (consumers) who are interested in the topics can simply listen to them and receive any data there in real time. This lightning fast transmission enables companies to react to circumstances fast. For example, a chat message could be sent quicker, bank transactions can also be much faster since every step of the process (e.g KYC/AML, fraud detection, settlement) are instantaneous, order inputs from customer in exchanges and e-commerce sites, too, can be processed to checked against order time, inventory, etc.
Kafka topics are managed by Kafka brokers, which partition the topics accordingly, handle consumer’s requests, make sure messages are sent to the right topics and get through to the correct consumers and that there are no data loss nor duplicates, etc. Multiple brokers also provide redundancy in case any is down for whatever reason, since the data is distributed, another will take its place and its data. Lastly, Kafka also uses a service called Zookeeper by another third party open source project Apache, which in turn keeps track of the state of clusters and nodes of brokers, consumers, and producers in a network.

Figure 1. A simple Kafka Message Queue
As we can see from figure 1. A single broker could in effect carry the message efficiently from many producers to many consumers. Also, remember that the process is parallel processing, meaning that a single pipeline actually consists of many parallel pipes, running at once. A single broker could also efficiently process messages of multiple topics and multiple partition.

Figure 2. Partitioned Topics
Solving redundancy and data loss problems, Kafka topics are generally divided into multiple partitions, each running separately from the others. This feature allows a partition to immediately take charge in case another partition is down for any reason at all. Brokers in turn divide any incoming message to different partitions for best performance. In practice, topics are generally divided into at least 3 partitions. In addition, partitions do not need to be in the same broker or even the same server and a single broker may consist of multiple topics and multiple partitions, strengthening its position.

Figure 3. A Kafka Environment
Figure 3 draws a more complete image of a Kafka environment. We can see that every Producers (ATMs) can send messages to any topics they want. Then consumers can get data from any topics that they need and disregard others. Topics in itself have multiple partitions that can be on a different Broker, which may also be on a different server altogether. All of this complex systems are orchestrated by the Apache Zookeeper.
What is your architecture like? And why Redpanda?
Naturally, Bitwyre chooses the battle-proven Kafka-API but with Redpanda messaging engine’s rapid speed as its streaming service due to its massive popularity, great environment and support, and more importantly, almost instantaneous message delivery by Vectorized. We implement it in a number of different, important ways. Most of which revolve around delivering time sensitive messages to-and-from different parts of our system.
If we’re tracking the process of a new order in our system, here's how it is done in our system, in a nutshell. First, your order goes through a system of gateways that receives it from your browser/app. From there, the gateways send Redpanda messages to our risk management engine, to see whether your order is valid or not. Then the risk engine sends another message with Redpanda to our matching engine, where trades are processed. Next, it sends another Redpanda message to another engine in order to settle the balance transfer to your account. Lastly, another Redpanda message is sent to the gateways in order to inform you about your order. In a single flow, we use 5 different engines all of which are time sensitive, thus we thought Kafka would solve this need.
Why Redpanda? Why not Kafka?
Even though Kafka solves a lot of problems in terms of speed and reliability, it still has its issues. The two important points are the necessary use of Zookeeper and JVM (Java Virtual Machine).
Kafka is written in the Java and Scala programming language. While not a bad programming language per se, it requires another program in order to run, the Java Virtual Machine (JVM). JVM acts as an intermediary between your machine and the Kafka written in Java. It works by creating a virtual environment on top of your computer in order to compile the human-readable Java code to machine-readable strings of zeros and ones that computers can understand. In short, JVM is a “mini computer” running above your computer. This has a double effect in both computing power and manpower.

Figure 4. JVM
First, JVM takes up valuable resources on the computer itself, making the process slower than expected, as we will see later in a comparison of Kafka and another alternative. The fact that in order to optimize Kafka in their use case and tinker with Kafka, or even simply to do some critical error-fixing, the developers need to be well versed in JVM. This contributes to the layer of complexity, as JVM developers are few and far between, and most developers who are using Kafka may well be unwilling to spend resources to learn another language, they just want Kafka to work flawlessly without much hassle. The solution of both of these problems is to increase computing power, and to either hire a Java expert with extensive experience in Kafka and distributed systems, or train your developers to do so, all of which requires significant investment.
Apache Zookeeper is a ubiquitous piece of software found mostly in big data settings. Its main purpose is to manage and orchestrate many nodes of servers/computers in a huge network of distributed computers. Zookeeper keeps all servers in sync with each other, saves everyone’s name and addresses, makes sure messages are sent to their destinations, manages configurations, etc. On first glance, it seems that Zookeeper is a wonderful thing to have, where in many cases, it does, especially in other Apache project’s systems. However, in Kafka’s particular use, it creates another overhead, since distributed computing is another expertise that many Kafka users don't have.
Tell me more about Redpanda's engineering prowess?
Redpanda tries to solve those two of Kafka’s problems quite elegantly. Firstly, it is written in C++, a low-level programming language that is more machine-language friendly than Java, and it does not require a virtual machine in order to compile, as it is directly processed by your computer, thus making it faster than Kafka, and easier to understand than having to learn Java and JVM. Redpanda also moves away from Zookeeper and instead uses an internally self configuring system, fetching your hardware details, tuning, configuring itself accordingly. These two solutions remove a lot of overhead from deploying a streaming service.
Better yet, Redpanda is also optimized for the development of newer hardware. Much like how disk storage prices have gone down and processing power has increased. Redpanda’s C++ is written to be optimized for a concept called Thread per Core. Given the fact that most modern CPUs have multiple cores, Redpanda also tunes it to the specifics of your CPU cores in order to create a more efficient parallel processing using a set number of cores.


Figure 5. No Zookeeper and JVM!
Another interesting fact about Redpanda is that, instead of creating a whole new environment and Application Programming Interface (API) from the ground up, it instead follows Kafka’s huge and diverse environment and API. This means that the input/output from Redpanda matches with those of Kafka, requiring no change in the user’s internal system, and it also supports other tools and applications related to Kafka in a plug and play fashion.
How is Redpanda's Developer Experience (DX)?
As mentioned previously, Redpanda has the same interface as Kafka, thus requiring a very simple transition from its predecessor. It is as simple as and as akin to changing the address on an mail. In a more technical manner, for example, we have Kafka set up at the IP address 10.10.10.1:9092. Thus every single service that uses Kafka sends and receives their files from that address. Then, if we configure Redpanda at 10.10.10.2:9093, we simply need to change the services to send and receive their data to the new address. Remember the APIs are compatible with Kafka! It's simply a string replace operation for your developer and operational team!
Nuff said, talk is cheap show us the...code results ? :)
To see what difference switching to Redpanda means to our performance, we conducted a simple experiment, in which we send a lot of order data to our servers, emulating how clients would place an order, then see how quickly our backend systems react to it. Our internal system uses Kafka, and later Redpanda, to convey messages from our frontend gateways (i.e. client-side gateways of our system) to our backends (our internal core system). Since the only changes are Kafka/Redpanda and nothing else, we can safely conclude that any difference in processing times are due to the changes in Kafka/Redpanda. We also do the same to a number of similar exchanges in order to create some form of baseline and comparisons.
Table 1. Kafka vs Redpanda Latency Testing
As we can clearly see from table 1, a switch from Kafka to Redpanda instantly creates a 19.5% boost in the average time of which data is transferred between our internal backend system, a cut of almost 0.1 seconds.
More significant, however, is the 44%, almost 1 second shaved in the higher percentile. This would be highly related to how stable our system is. For now, let us explore the data a bit more.

Figure 5. Kafka vs Redpanda Time Distribution

Figure 6. Kafka vs Redpanda Outliers
The two graphs in figure 5 and 6 tells the same story, that Redpanda significantly reduces latencies and improves performances in tail data. What is a tail? For example, there are 1000 orders that got through Bitwyre’s system. In a perfect world, all of these orders would be processed at the same rate. However, in reality, a lot would be processed slower than the average, and very little, though not zero, would be processed way slower than usual. Those little bits who are unlucky are considered tails, with implications explained further in the article
We can see from figure 5 that both Kafka and Redpanda have the same average as mentioned in Table 1, 0.46 and 0.37 seconds respectively. Going further to the right (the so-called right-hand tails), things are starting to be quite different. We can see that in Redpanda, the probability of processing time declines sharply and becomes extremely small after the 1 second mark. However, in Kafka, even after it drops at 1 seconds, it keeps roller-coastering up-and-down deep into 2 seconds. Even then, the graph in the tails is somewhat thicker for Kafka than Redpanda, and goes further near the 6 seconds mark.
We can see the tail even clearly in figure 6, a box-whisker plot, which explains the data in their quartiles and the tail outliers. Dots above the whisker line are considered outliers, and in Kafka, the number and range of outliers are clearly greater than Redpanda.
Now let us explore how switching impacts our internal, backend system. Belows are the statistics for Kafka vs Redpanda on our internal messaging systems

Figure 7. Time Distribution, Kafka vs Redpanda on Bitwyre’s Gateway to Matching Engine
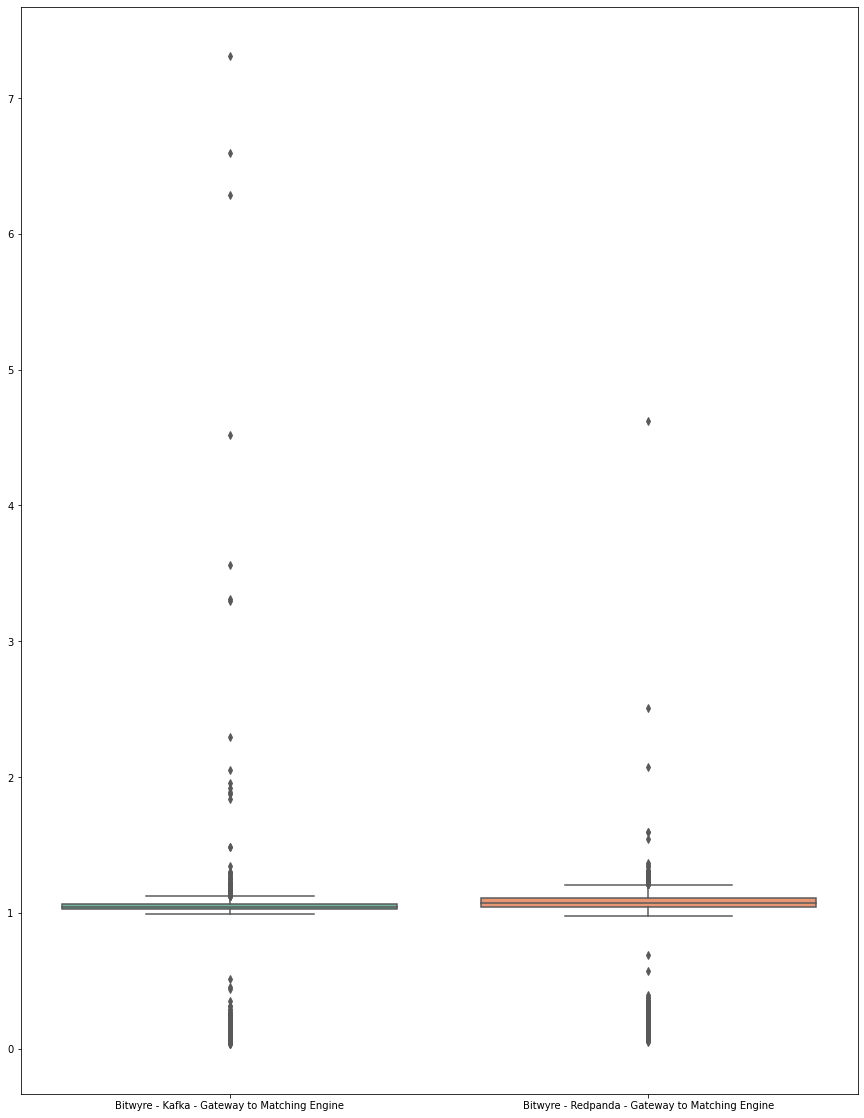
Figure 8. Box Plot, Kafka vs Redpanda on Bitwyre’s Gateway to Matching Engine
Figure 7 and 8 explains how long it takes for messages to be received by our Matching Engine, from our front-end gateways. They illustrate the processing time from a new order creation to acceptance to our matching engine. Only orders that are accepted by the matching engine are valid for trade, thus any lag would mean lost opportunity since there may be price or volume movement.
Next we will see the improvement from the Matching Engine to our Depth Feed Engine

Figure 9. Kafka vs Redpanda on Bitwyre’s Matching Engine to Depth Feed Engine

Figure 10. Boxplot - Kafka vs Redpanda on Bitwyre’s Matching Engine to Depth Feed Engine
Figure 9 and 10 describes how long from being accepted to the system the orders have to go to actually inserted to the orderbook by depth feed engine, thus open to the market. Even though orders have been accepted, if it's not on the orderbook, it would not get any trade or listed to be traded.

Figure 9. Kafka vs Redpanda on Bitwyre’s Matching Engine to Credit Risk Engine

Figure 10. Boxplot - Kafka vs Redpanda on Bitwyre’s Matching Engine to Credit Risk Engine
Figure 9 and 10 explains how long it takes for messages to be received by our Credit risk engine, from our matching engine.
As we can see from the set of graphs, Redpanda is superior due to lower latency on all parameters. Even better, the tail ends and outliers are significantly less than Kafka. And lastly, here are the numbers between Bitwyre’s own exchange versus a number of other global exchanges using the order method as on table 1.
Table 2. Kafka vs Redpanda Latency Testing

Figure 9. Distribution of The Exchanges

Figure 10. Box-Whisker Plot of The Exchanges
It is as we have discussed, that the exchanges with the best latency, which are OKEx and Binance, have a very low tail and very small outliers, as their system is robust. The reverse can be said with BitMex which have a higher average latency, from which we can assume a less robust system, has a wide spread of tail and outliers.
Conclusion
Performance in low-latency engines are considered by how they handle outliers and tails. Time is of the essence, and systems cannot afford a single loss and low predictability, one could spell disaster.
For example, consider the volatile Cryptocurrency market, where prices move in a blink of an eye. Let’s say John is going to buy one Bitcoin at the price of $1000, and promptly create an order at our exchange. However, the low predictability of our system makes his order arrive 1.5 second later than the average. This would mean that either John has to buy Bitcoin at another, possibly way higher prices, maybe $1100, or unable to buy at all.
On the flip side, let's say John has one Bitcoin, and is willing to to sell it at the price of $1000. His sell order got stuck in the messaging system and is a couple seconds late, and right now Bitcoin price has fallen to $900. John is now at a $100 loss due to the inefficiencies in the system.
Another example, say there is only a single Bitcoin in stock inventory at the price of $1000, John creates an order right now to buy that last stock. In the meantime, half a second later, Jane also sees the last stock and buys the same Bitcoin. Due to the system’s outlier, John’s orders are registered 2 seconds later, but Jane’s are processed in less than one, thus the system registers that Jane is the rightful owner of the coin, even though, as John orders first, it should be his. Now multiply these three examples by thousands of times, each worth hundreds if not thousands of dollars. A nightmare indeed.
It is imperative that we keep our outliers as small as possible, without necessarily creating a lot of overhead and unnecessary costs in our system. From the graphs, it is clear that Redpanda is superior to Kafka, thus changes are almost sure. Because of Redpanda’s use of the ever popular, industry wide Kafka API and tools, the move from Kafka to Redpanda is as easy as changing only a handful lines of codes. Moreover, due to the innate nature of Redpanda which does not require Java and JVM expertise, developers could rest easy that their program would run as efficiently as possible in their machine without any further modifications. Also, the lack of Zookeeper means organizations does not have to invest in distributed system specialists, and since it does not need another layer of processing power, saves on hardware costs.
Appendix
Internal latencies
- Gateway to matching engine


- Matching Engine to Order Confirmation


- Matching Engine to Depth Feed Engine


- Matching Engine to Websocket Depth Feed Engine

